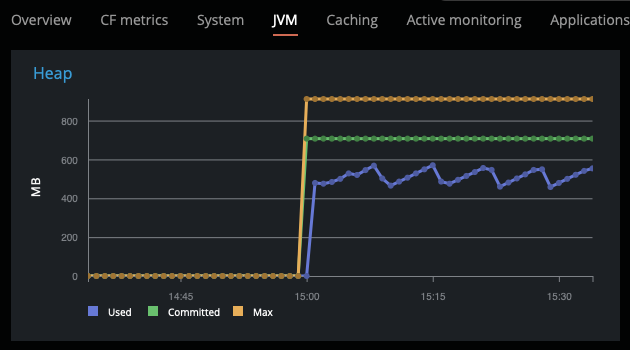
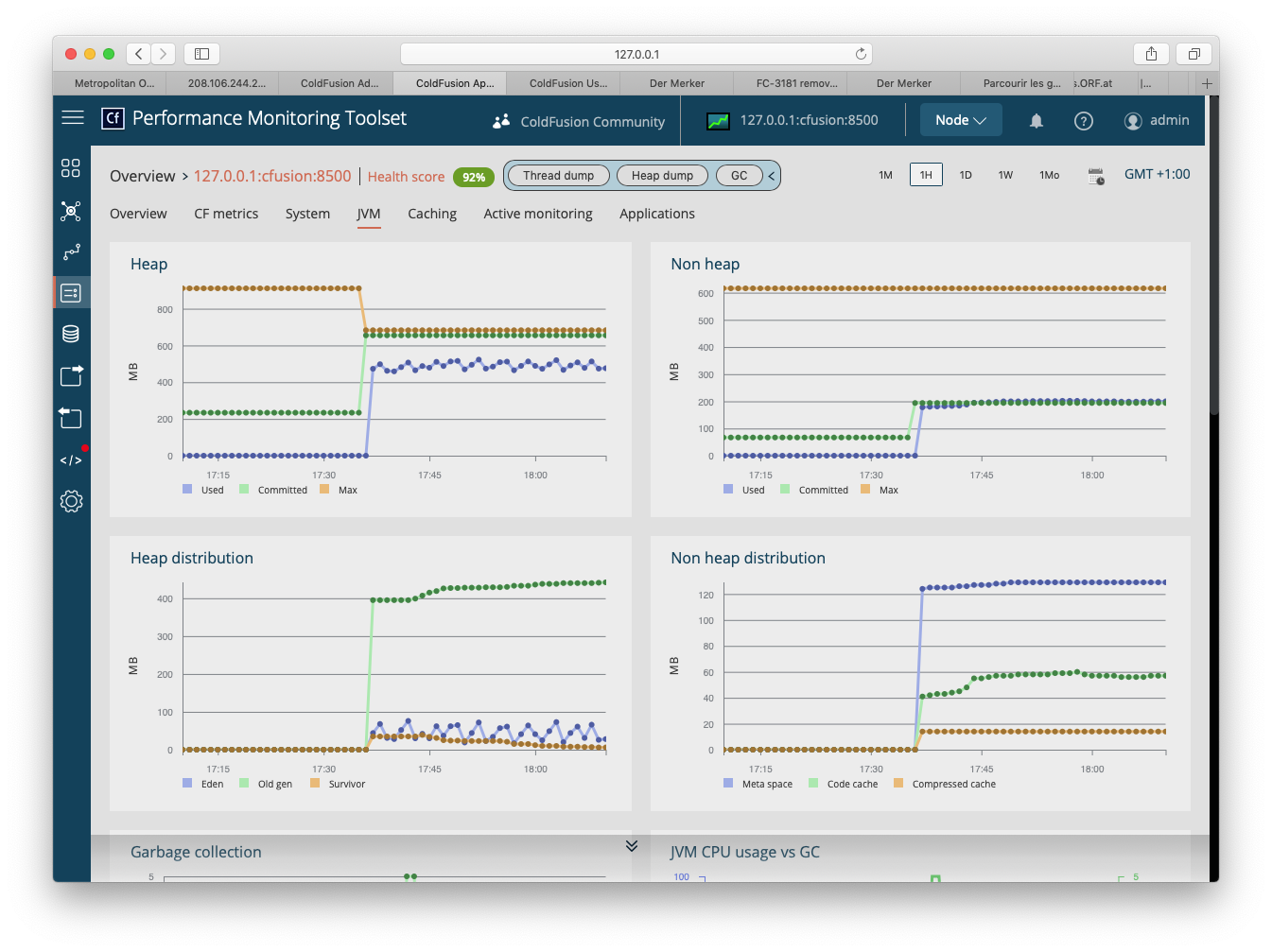
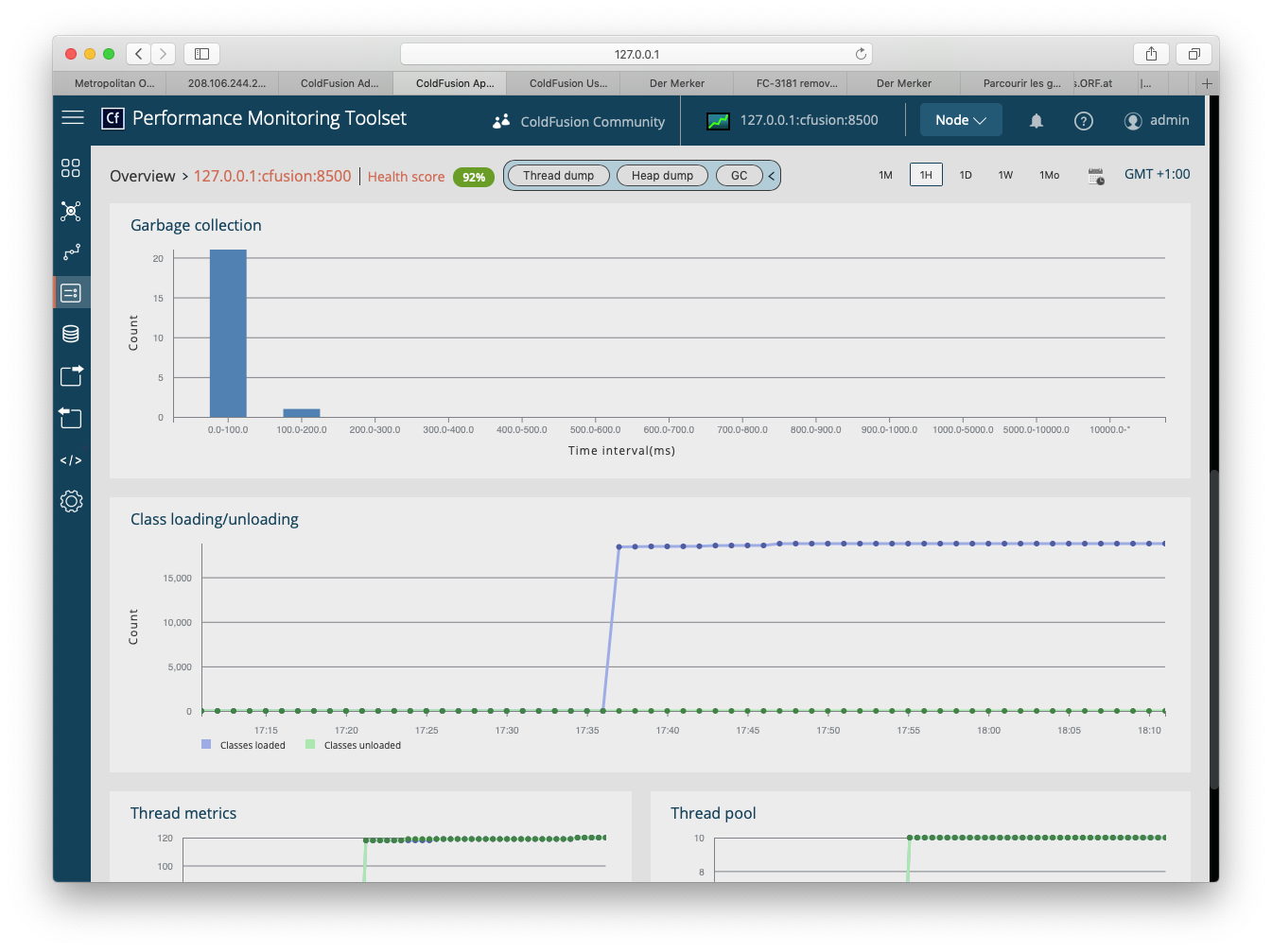
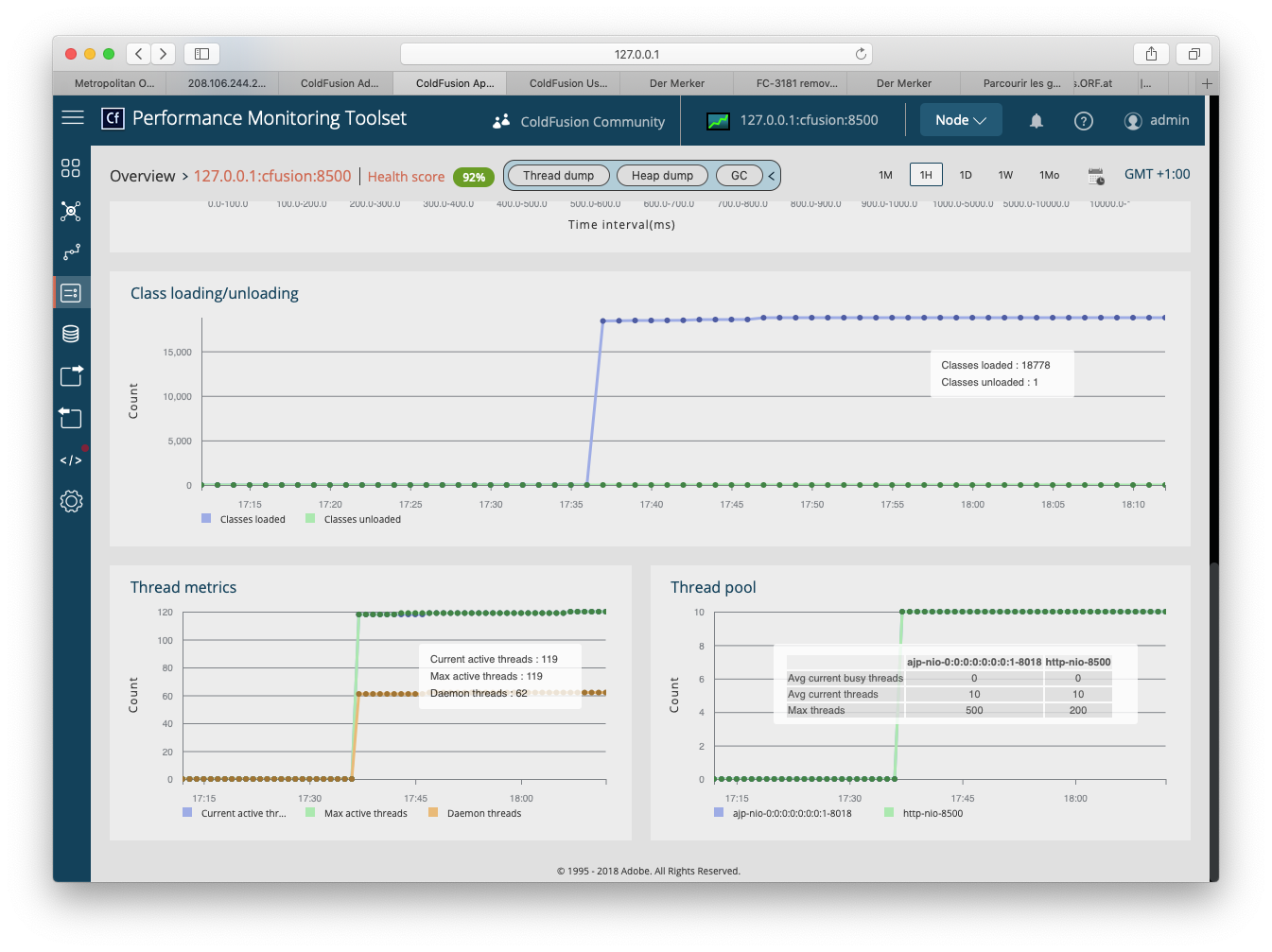
My hosting provider informed me that my site (FarCry 7.2.9, CF11 on Windows Server 2012/AMD64 v 6.2) allocates too much memory. (They claim more than 1 GB.) Having looked up the object broker settings in the FarCry backend admin section, I could not find anything out of the ordinary. It is a small site with approximately 20 dmHTML items, 400 dmNews items and, currently, 500 dmImage items. Each of the dmImage items contains three versions of images with an average total size of 300 kB per content object.
Usually, people don’t scan the entire site – which could bring the cached objects to the FarCry preconfigured limits of 1000 instances per object type – but are only interested in the latest news/articles. Also, I don’t use the friendly URl function.
I use the skin:cache feature on all dmNews and dmHTML pages with the command shown below and a caching time of 14 or 1 day(s) respectively:
<skin:cache cacheBlockName=“page”
cacheName="_#stObj.objectID#_displayPageStandard"
days="#application.config.general.ttl.pageGeneral#">
Has anybody experienced anything similar? Do I overlook anything? Is it possible that bots and crawlers which parse the entire site will fill the object broker cache in the application scope?
And, more important: Which actions can I take to bring down the memory footprint significantly in order to avoid the site being shut down?
Any suggestions are greatly appreciated.
Thank you,
Thomas